C言語のchar型で全角文字を扱う際のイメージを解説します。
そもそもchar型は基本的に1バイトで表現できるASCIIコード文字(⇒ASCIIコード表)を扱うためのデータ型です。
基本的char型は、半角文字(キーボードから直接入力可能な0~9, a~z, A~Zや記号など)を格納するためのものです。
char型は、日本語の全角文字に対応していないので利用しない方が得策です。
と、言ってしまっては元も子もないので、解説します。
全角文字をchar型配列に格納してみる
以下のようなプログラムはきちんと動作します。
zenkaku.c
#include <stdio.h>
int main(void)
{
char str[] = "おはよう";
printf("%s\n", str);
return 0;
}
実行イメージ
おはよう
この場合、配列のイメージはこうなっていると考えてください。
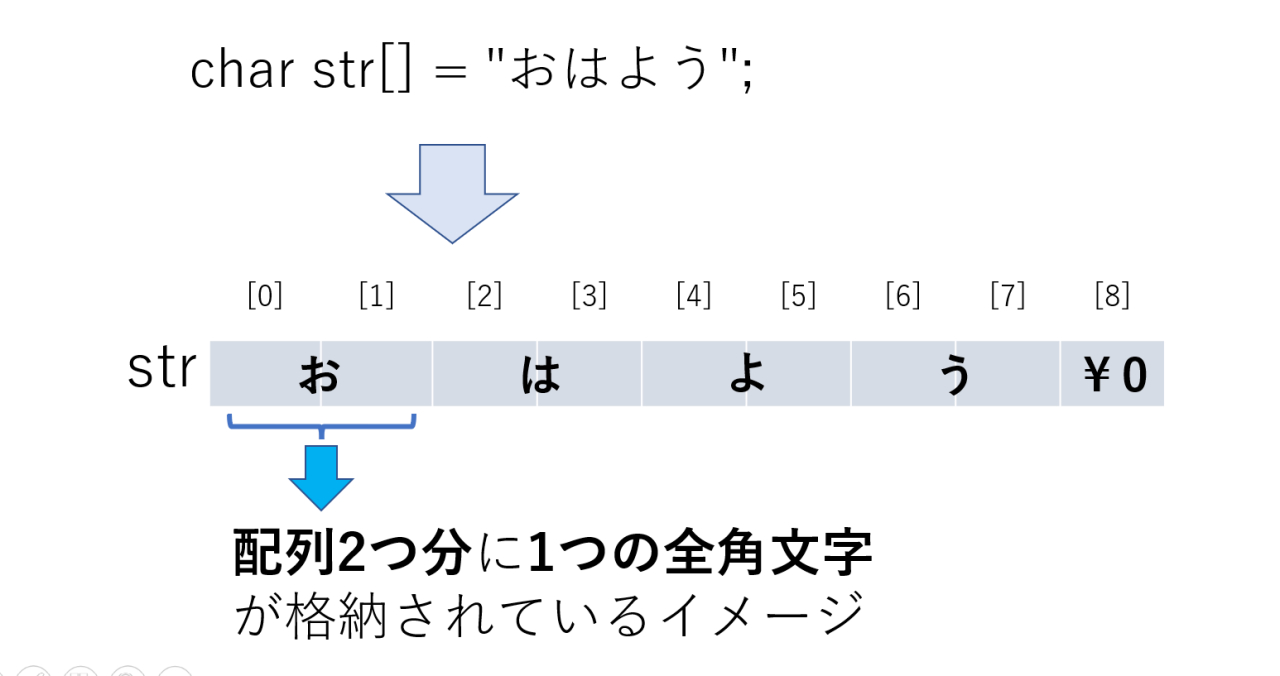
日本語の漢字・ひらがな・カタカナは全角文字と呼ばれ、ASCIIコード表にはない文字です。
全角文字をchar型に入れることはできるが無理があるということです。
それが証拠に以下のように配列str[0]を個別に取り出そうとすると変な文字が表示されます。
#include <stdio.h>
int main(void)
{
char str = "おはよう";
printf("%c\n", str[0]);
return 0;
}
表示イメージ
[馨
printfなどでchar型配列に格納した全角文字の全体を表示する場合は問題ありませんが、配列要素を1つずつ取り出そうとするとうまくいかないということです。
文字コードによるバイト数の違い
今回は説明のため全角1文字を2バイト分でイメージしましたが、実際は文字コードによって全角文字1文字分のバイト数は様々です。
Shift-JISの場合は、上記のイメージ図通り、全角1文字が2バイト分です。
最近のデファクトスタンダードとなっているUTF-8は全角1文字が基本は3バイトですが、一部の文字は4バイトとなります。
プログラムで全角文字のバイト数を確認してみる
次のようなsizeofを使ったプログラムを作ると配列に代入した文字のバイト数が分かります。
zenkaku_byte.c
#include <stdio.h>
int main(void)
{
char str1[] = "漢字";
char str2[] = "ABCD";
printf("[%c]\n", str1[0]);
printf("%s\n", str1);
printf("size = %d byte\n\n", sizeof(str1));
printf("%s\n", str2);
printf("size = %d byte\n", sizeof(str2));
return 0;
}
実行イメージ(環境によりバイト数の表示は異なります)
漢字 size = 5 byte ABCD size = 5 byte
コンピュータがアメリカ発祥ということで、日本人にとっては色々と分かりにくい部分が多いですね。
以上、C初級:日本語などの全角文字をchar型で扱う際のイメージでした。


コメント