
PythonとBeautifulSoup4を使って「10行でターミナルからこっそり誰かのTweetをチェックする」という事をやってみます。
まずはbeautifulsoup4をインストール
ターミナル(またはコマンドプロンプト)から
pip install beautifulsoup4
又は
pip3 install beautifulsoup4
でインストールできます。
ちなみにbeautifulsoup4は、スクレイピングによく使われるPythonのライブラリです。
今回は、Twitterのフォロワー数が多いと言われている有名人の有吉弘行さんのTwitterをこっそりチェックしてみました。
こんな感じで取得できました。(Windowsのコマンドプロンプトにて実行)
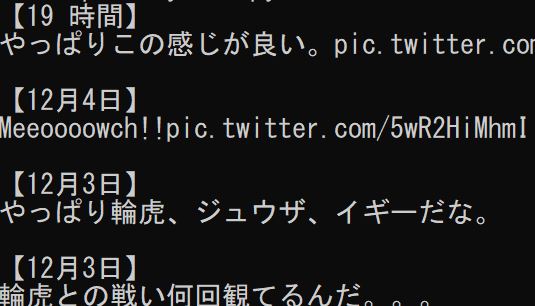
ちなみに有吉弘行さんの公式Twitterは以下です。
有吉弘行 – Twitter (https://twitter.com/ariyoshihiroiki)
プログラムです。
今回はちょうど10行です。(最後の10行目がかなり長いですが…)
10linesCheckTweet.py
# -*- coding: utf-8 -*-
import urllib.request
from bs4 import BeautifulSoup # BeautifulSoup4をインポート
url = "https://twitter.com/ariyoshihiroiki" # チェックしたいTwitterのURL(有吉弘行)
data = urllib.request.urlopen(url) # Twitterを読み込む
soup = BeautifulSoup(data, 'html.parser') # HTMLをプログラムから扱えるように変換
tweets = soup.find_all("div", class_="js-tweet-text-container") # つぶやき部分のタグを取得
timestamps = soup.find_all("small", class_="time") # つぶやいた時間部分のタグを取得
for i in range(10): # 最新10件
print("【{0}】{1}".format(timestamps[i].find_all('span')[len(timestamps[i].find_all('span')) - 1].text, tweets[i].text) ) # つぶやき(1件分)を表示
解説
2行目と3行目
import urllib.request from bs4 import BeautifulSoup # BeautifulSoup4をインポート
必要なライブラリのインポートです。
サイトデータの取得にurllib.request、スクレイピングにBeautifulSoupを使います。
4行目、有吉弘行さんのTwitterアドレスです。(適当に見たい方のTwitterに置き換えてください)
url = "https://twitter.com/ariyoshihiroiki" # チェックしたいTwitterのURL(有吉弘行)
5行目 Twitterサイトからデータを取得します。
data = urllib.request.urlopen(url) # Twitterを読み込む
6行目 BeautifulSoup4の出番です。html.parserというのは取得したサイトデータをプログラムで扱えるようにするための変換処理です。
soup = BeautifulSoup(data, 'html.parser') # HTMLをプログラムから扱えるように変換
7行目 つぶやき部分のみリスト配列に代入します。beautifulsoup4のfind_allメソッドはリストで返します。ちなみにdivタグのクラス名js-tweet-text-containerの中身がつぶやき部分です。
tweets = soup.find_all("div", class_="js-tweet-text-container") # つぶやき部分のタグを取得
8行目 つぶやいた時間(タイムスタンプ)を同じくリスト配列に代入します。こちらはsmallタグのクラス名timeにつぶやいた時間の文字列が入っています。
timestamps = soup.find_all("small", class_="time") # つぶやいた時間部分のタグを取得
9行目と10行目 最新の10件を表示しています。rangeの引数は10としてあるので最新の10件という意味です。適当に変更してください。
for i in range(10): # 最新10件
print("【{0}】{1}".format(timestamps[i].find_all('span')[len(timestamps[i].find_all('span')) - 1].text, tweets[i].text) ) # つぶやき(1件分)を表示
実は最後のprint文で当初はformat文の引数を
timestamps[i].text
として単純に表示したのですが、時間の表示が
19 時間19 時間前
などと変な表示になってしまったため調べてみると、経過時間によって「12月3日」などと日付のみだったり、「10 時間」「10 時間前」などと2件のタイムスタンプ文字列が入っていることが判明しました。つまりデータが1件の場合と2件の場合があったわけです。
よって最初に考えた引数部分を
timestamps[i].find_all('span')[len(timestamps[i].find_all('span')) - 1].text
と修正しました。
正直この1行は、10行プログラムにするために凝縮したものなので、なんだか訳のわからないプログラムです。
複数行に直すとこんな感じになります。(少しは分かりやすく見えますでしょうか?)
9行目と10行目部分(わかりやすいように修正)
for i in range(10): # 最新10件
# 複数あるタイムスタンプ文字列の最後のインデックス
lastIndex = len(timestamps[i].find_all('span')) - 1
# タイムスタンプ文字列を全て取得
timestamp = timestamps[i].find_all('span')
print("【{0}】{1}".format(timestamp[lastIndex].text, tweets[i].text) ) # つぶやき(1件分)を表示
一応タイムスタンプが2件の場合は、後ろの方のデータを取得するようにしています。その方が「10 時間前」などと時間の後に「~前」の文字がつくので。
以上、いかがでしたか?10行でつぶやきが取得できましたか?
これで仕事中にターミナルからこっそりつぶやきチェックできますね!笑(注)わたしはしてません。
以上、10行でターミナルからこっそり誰かのTweetをチェックする、でした。
コメント