タイトルの日本語が変ですが、それ以上に日本人がWindowsを使っていると変なことが勃発します。
文字化け問題
です。
この記事では、gccコンパイラを使ってコンパイルした実行ファイルが、コマンドプロンプト上で文字化けしてしまうことに関する対処法を、どうしてそうなるのか?という部分も含めて長々と解説します。(笑)
結論を教えて欲しいという方のために最初に結論を書いておきます。
1.C言語ソースファイルは、文字コードUTF-8で保存する
2.gccによるコンパイルは、-fexec-charset=CP932 スイッチをつけてコンパイルする
【コンパイル記述例】
gcc -fexec-charset=CP932 -o hoge hoge.c
※hoge.cというCソースファイルをhoge.exeとして実行形式出力する場合
2023-07-06 追記
「こちらの方が楽ですよ」とnscさんからコメントいただいた福岡工業大学山本研究室の資料を紹介しておきます。
以下の資料では、CソースコードをShift-JISで保存する形の設定となります。コンパイラもgccではなくマイクロソフトのcl.exeでの方法となりますが、設定方法はとても参考になります。
http://imgprolab.sys.fit.ac.jp/~yama/CProI/lec/VScode_CodeRunner_Install.pdf
2020-12-05 追記
Visual Studio CodeのCode Runnerでこれをやりたいんだよー、という方は以下のリンクに設定方法を書いておきましたので参考になさってください。
前置きとして
この記事で扱うのは、以下のような半角英数文字が画面に出力や入力される際の話ではありません。
#include <stdio.h>
int main(void)
{
printf("Hello mojibake!!!\n");
return 0;
}
上記のような半角文字(1バイトで表現できるため、バイト文字と呼ばれる)を出力したりするプログラムは全く問題ありません。なぜなら文字コードがUTF-8でもShift-JISでもアルファベットのABCなどは文字コードが同じだからです。文字コードが同じで同じ文字を表すなら文字化けはしません。
問題は、以下のような全角文字(2バイト以上で表現するため、マルチバイト文字と呼ばれる)を使って入出力を行う場合です。
#include <stdio.h>
int main(void)
{
printf("文字は文字コードで表現されます\n");
return 0;
}
gccコンパイラでマルチバイト文字を扱ったCソースコードをコンパイルしてWindowsのコマンドプロンプト上で実行すると色々な問題が生じます。(色々といっても「文字化け」がほとんどなんですが、文字化けのバリエーションが豊富なので「色々」と言わせてもらいます)
それでは順を追ってCソースコードも交えて解説します。
日本語が文字化けあるいはコンパイルエラーが出る例と対処法
CソースコードをShift-JISで保存しコマンドプロンプト上でそのまま実行
これは一見問題なさそうなので、わたしは騙されました。
例えば以下のCプログラムをコマンドプロンプト上でコンパイルし、実行したとします。
hoge.c
文字コード:Shift-JISで保存
#include <stdio.h>
int main(void)
{
printf("右も左も分かりません!\n");
return 0;
}
コンパイル例
gcc -o hoge hoge.c
実行結果(コマンドプロンプト上で hoge [Enter]で実行)
右も左も分かりません!
文字化けもなく全く問題なさそうです。
しかし、printf関数で指定した文字列「右も左も分かりません!」の部分を次のように変えてコンパイルしてみます。
printf("文字は文字コードで表現されます\n");
コンパイル結果
test.c: In function ‘main’:
test.c:5:9: warning: unknown escape sequence: ‘\214’
5 | printf(“n”);
5行目、つまり
printf("文字は文字コードで表現されます\n");
の部分でエラーがでています。もう少し詳しく言えば「表」の文字部分でエラーが出ます。
これはShift-JISコードの「表」の文字コードはUTF-8では扱えないことを意味します。gccコンパイラは内部では文字列をUTF-8として認識してコンパイルするので、こうした問題がでてきます。
「表」の文字は先頭部分が「\」と同じ文字コードを表していてエスケープシーケンス文字(制御文字)として扱われることになってしまいます。UTF-8では「表」の文字コードの先頭が「\」とならないため問題はありませんが、Shift-JISだと問題になってきます。
CソースコードをUTF-8で保存しコマンドプロンプト上でそのまま実行
そこで先ほどのCソースファイルをgccコンパイラに合わせて、文字コードUTF-8で保存してみます。(以下はメモ帳での保存例)
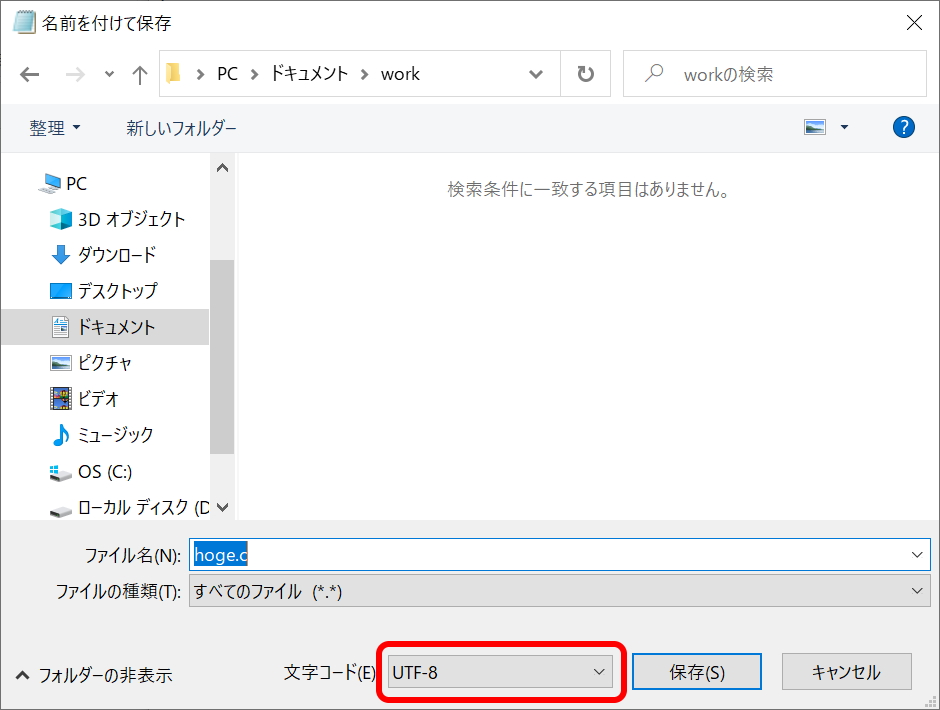
コンパイルは問題なく通りました。
それでは実行!
譁・ュ励・譁・ュ励さ繝シ繝峨〒陦ィ迴セ縺輔l縺セ縺・
やってきました文字化け!
理由は簡単で、UTF-8で保存してコンパイルしたCソースファイルをShift-JISで入出力を行うWindowsコマンドプロンプト上で実行したからです。
Windowsのコマンドプロンプトは出力をUTF-8にすることも可能なので一時的にコマンドプロンプトの出力をUTF-8にしてみます。
UTF-8で保存してgccコンパイルした実行ファイルをコマンドプロンプトのUTF-8モードで実行
コマンドプロンプトの出力文字コードをUTF-8にする命令は以下になります。
chcp 65001
上記をコマンドプロンプト上で実行すると、モードがUTF-8に切り替わった旨が表示されます。
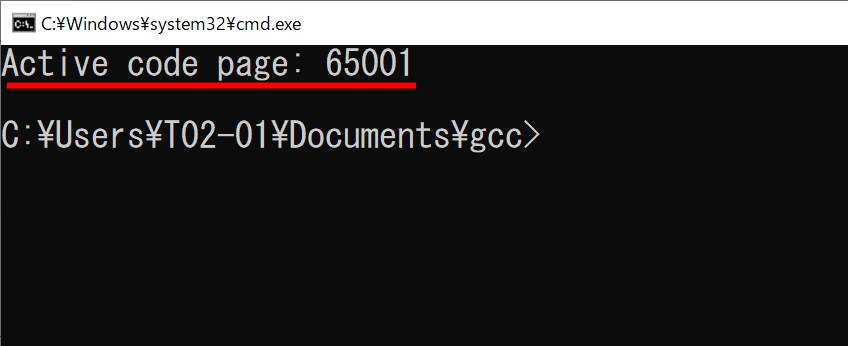
この状態で先ほどのプログラムを実行してみます。
実行結果
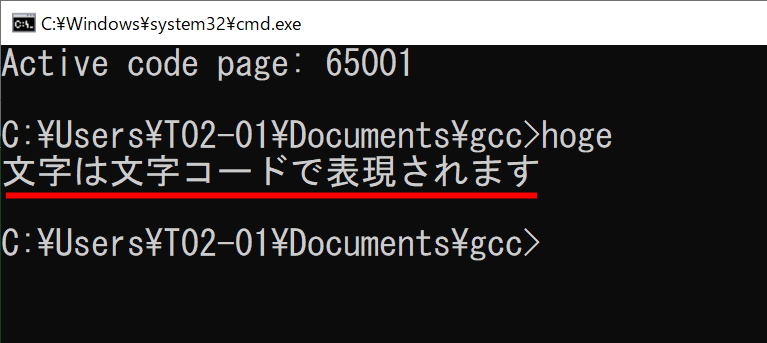
バッチリです……と言いたい所ですが、実はまだ問題があります。
scanf関数などで入力を伴うCプログラムの場合です。
ファイル保存形式とコマンドプロンプト出力をUTF-8に合わせてもコマンドプロンプト上でscanf実行すると文字列が読み取れない
《CプログラムをUTF-8の文字コードで保存した》
《コマンドプロンプトもchcp 65001を実行してUTF-8モードにした》
これだけすればマルチバイト文字列の出力(表示)に関しては問題ないですが、コマンドプロンプト上でscanf関数によるマルチバイト文字入力の際、不具合が出ます。
次のコードをご覧ください。
#include <stdio.h>
int main(void)
{
char buf[256];
printf("文字を入力してね: ");
scanf("%s", buf);
printf("入力結果: %s\n", buf);
return 0;
}
実行結果
文字を入力してね: トマト [Enter]
入力結果:
実行結果が「入力結果: トマト」となるはずが何も表示されていません。コマンドプロンプト上での入力がうまくいっていない可能性があります。
文字列の一致を判定するstrcmp関数も試してみました。
hoge2.c
#include <stdio.h>
#include <string.h>
int main(void)
{
char kotae[256];
printf("信号機の一番右は何色? ");
scanf("%s", kotae);
if(!strcmp(kotae, "赤")){
printf("正解!\n");
}
else{
printf("ぶっぶー\n");
}
return 0;
}
キーボードから「赤」と入力すると「正解!」と表示されるはずなのですが、実行結果はこうなりました。
信号機の一番右は何色? 赤 [Enter]
ぶっぶー
文字列一致判定がうまくいっていません。やはり入力された時点で入力がうまくいっていない可能性があります。コマンドプロンプトをUTF-8モードにしても入力までUTF-8になっている訳ではないようです。
わたしは最終的に以下の方法でこれをクリアすることにしました。
gccコンパイル時に実行ファイルの処理をShift-JISに置き換えるスイッチをつけてコンパイルする
gccコンパイラにはコンパイル時に色々なスイッチがあります。その中で、Cソースファイルの保存形式はUTF-8のままで、実行ファイルの処理はShift-JISとして実行する、というスイッチがあります。今回はこれを採用してみます。(…というかこれが今回の結論です)
コンパイル方法
gcc -fexec-charset=CP932 -o hoge hoge.c
gccコンパイル時に -fexec-charset=CP932 を追加するだけです。
あと、もしコマンドプロンプトの出力をchcp 65001でUTF-8に変えていた場合は、コマンドプロンプト上で「chcp 932」と入力してShift-JISに戻しておいてください。
実行結果
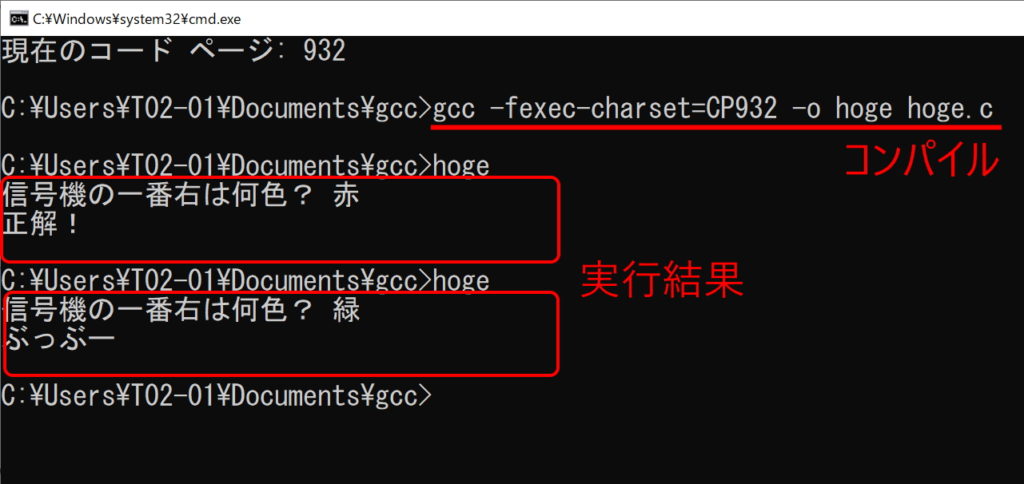
きちんと実行できています。
以上見てきたようにWindowsのコマンドプロンプト上でgccコンパイルしたファイルを実行しようとすると色々なマルチバイト文字に関する文字化けや不具合が発生します。
というわけでまとめておきます。
まとめ
Windowsのコマンドプロンプト上でgccコンパイルしたCプログラムを文字化けせずに実行する方法
| C言語ソースファイル | 文字コードをUTF-8で保存する |
| コマンドプロンプト | 通常通り起動する(Shift-JISモード) |
| コンパイル方法 | gcc -fexec-charset=CP932 -o 《実行ファイル名》 《C言語ソースファイル名》 記述例)gcc -fexec-charset=CP932 -o hoge hoge.c |
以上が現時点でわたしの中でのベストな方法です。
他の方法があればぜひ教えていただければと思います。
以上、Windows:コマンドプロンプト上でgccコンパイルした実行ファイルが文字化けしない方法でした。
コメント
初めまして。
このページで紹介している「Cソースファイルの保存形式はUTF-8のままで、実行ファイルの処理はShift-JISとして実行する」ということを試しているのですが、
「gcc -fexec-charset=CP932 -o ○○○.c」と入力しても
「gcc.exe: error: gcc: No such file or directory」
「gcc.exe: fatal error: no input files」と表示されます。
何が原因でしょうか。
こんにちは、タマカさん。管理人です。
まずは気になった点を記述しておきます。
> 「gcc -fexec-charset=CP932 -o ○○○.c」と入力しても
とありますが、-oの次はC言語ソースファイルを記述してはいけません。
例としてabc.cというC言語ソースファイルをコンパイルしたい場合、
などとします。するとabc.exeという実行形式ファイルが生成されるので
でコマンドラインから実行できます。
上記のようにコンパイルして同じようなエラーがでるようであればまた別の原因が考えられます。
管理人様
正常に動作しました!
丁寧なアドバイスを頂きありがとうございます。
エラーの原因は「-o」と「○○○.c」の間にファイル名が入力していなかったことでした。
また、サンプルプログラムの「hoge hoge.c」というC言語ソースファイルだと思い込んでしまったことも原因でした。
改めて、ありがとうございました。
良かったです!
福岡工大の以下のサイトのやり方はとても楽のような気がしますが、いかがでしょうか?
chrome-extension://efaidnbmnnnibpcajpcglclefindmkaj/http://imgprolab.sys.fit.ac.jp/~yama/CProI/lec/VScode_CodeRunner_Install.pdf
nscさん、貴重な情報ありがとうございます!
紹介いただいたサイト確認させて頂きました。確かにこちらの方が楽な方法だと思います。
紹介された方法とわたしの記事との大きな違いは、C言語ソースコードの文字コードの保存方法です。
紹介サイトでは、Shift-JISでC言語ソースコードを保存しています。
わたしの記事では、UTF-8でC言語ソースコードを保存しています。
UTF-8にした理由は1つありましてShift-JISが今後利用されなくなるだろうと考えられるからです。
Windowsのメモ帳も以前はShift-JISがデフォルトでの保存形式でしたが、最近(Windows10以降)は、UTF-8がデフォルト設定になりました。
UTF-8が現在の流れとして主流になってきました。
個人的にどうしてもUTF-8でソースコード自体は保存・編集したかったというのもあり、このような面倒な方法となっています。
ただ、紹介いただいた方法はとても参考になりました。ありがとうございます。本記事に参考追記として紹介させて頂きます。