次のような文字列から数値部分のみを取り出して利用したいときがある。
1,980円
ここで取り出したいのは、1980という数値のみだ。途中の「,」やk「円」の文字は省きたい。
サンプルコード
正規表現にある\Dという特殊シーケンスと正規表現モジュールreのsubメソッドを使って以下のようにすると取り出せる。
import re string = '1,980円' num = re.sub( r'\D', '', string) print(num)
実行結果
1980
解説
正規表現操作を使うため reモジュールをインポートしている。
import re
subメソッドは文字列置換を行う。
re.sub( 正規表現パターン, 置換する文字列, 文字列 )
サンプルでは置換する文字列に ” (シングルクォーテーション2つ)を指定しているため、正規表現パターンと一致した文字列は削除される。
re.sub( r'\D', '', '1,980円' )
正規表現パターンの\Dは数値以外を表す。すなわち数値以外と一致した場合は削除することになる。
r’\D’となっている先頭のrはエスケープシーケンス文字\を無効化する意味をもつ。
正規表現ではよく用いられる。
ちなみに \D と同じ「数値以外」を表す意味の [^0-9] を利用しても同じ処理ができる。
import re string = '1,980円' num = re.sub( '[^0-9]', '', string) print(num)
実行結果
1980
参考

re --- 正規表現操作
ソースコード: Lib/re/ このモジュールは Perl に見られる正規表現マッチング操作と同様のものを提供します。 パターンおよび検索される文字列には、Unicode 文字列 ( str) や 8...
docs.python.org
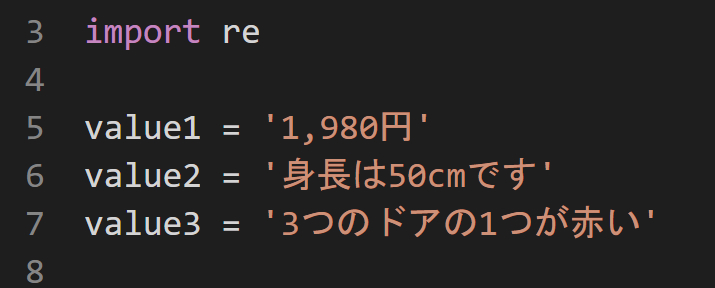
サンプルコード2
数値が含まれるいくつかの文字列で試してみた。
re_sub_get_number.py
# 正規表現で文字列中の数値のみを取り出す
import re
value1 = '1,980円'
value2 = '身長は50cmです'
value3 = '3つのドアの1つが赤い'
pattern = r'\D' # 数値以外を表す [^0-9]と同じ意味
number1 = re.sub(pattern, '', value1)
number2 = re.sub(pattern, '', value2)
number3 = re.sub(pattern, '', value3)
print('number1: {}'.format(number1))
print('number2: {}'.format(number2))
print('number3: {}'.format(number3))
実行結果
number1: 1980 number2: 50 number3: 31

コメント